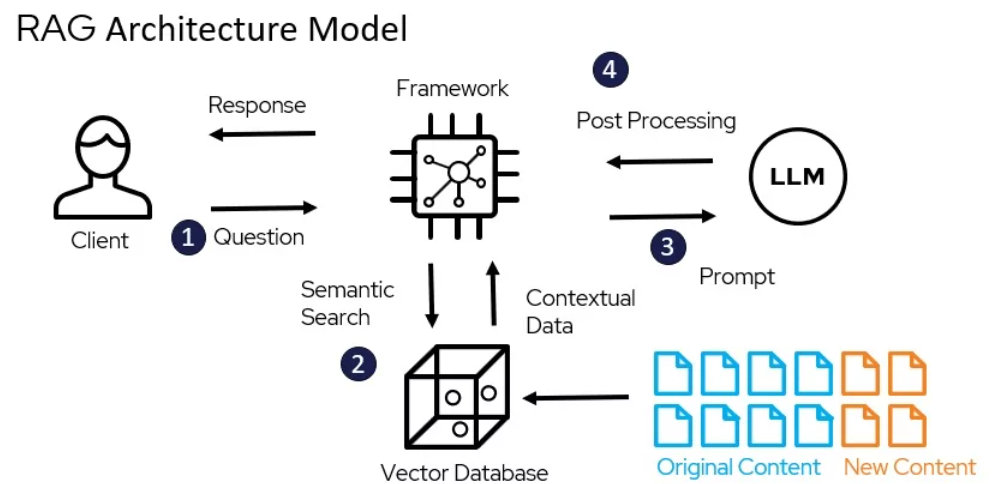
Retrieval-augmented generation (RAG) is a hybrid approach that enhances the capabilities of generative models by incorporating relevant information retrieved from a large corpus. RAG Techniques involves three main steps:
1. RAG Pre-Retrieval Optimisation
The pre-retrieval is a foundation step of Retrieval-Augmented Generation systems. It involves preparing the data, storing it efficiently, and indexing it for quick and accurate retrieval. This phase ensures that the RAG system operates smoothly and effectively, providing high-quality inputs for the generation phase.» Data Preparation and Cleaning:
- Deduplication: Deduplication is a vital process in data management that eliminates redundant copies of data. This is one of the RAG Techniques which ensures that each piece of information is unique within a dataset, which can significantly improve storage efficiency and data processing speed.
- Normalization: Normalization involves transforming text into a standard format, enhancing the data’s consistency and reliability. Removing Punctuation and applying Stemming and Lemmatization are crucial techniques for uniform data.
- Filtering: Perform Topic Modeling and Keyword Filtering to remove low-quality, irrelevant, or noisy data and ensure the dataset remains clean and relevant for generation.
» Data Storage and Indexing:
- Inverted Indexing: This method maps terms to their locations in the corpus, allowing for rapid search and retrieval of documents containing specific terms. Inverted indexes are foundational in search engines, enabling efficient querying of large text corpora.
- K-D Trees: These data structures organize points in a k-dimensional space, facilitating efficient range queries and nearest neighbor searches. They are helpful in high-dimensional data retrieval scenarios.
- Hierarchical Navigable Small World (HNSW): HNSW is an advanced indexing technique that builds a graph-based structure for fast and scalable approximate nearest neighbor search. It balances the trade-off between accuracy and search speed, making it suitable for large-scale retrieval tasks.
2. RAG Retrieval Optimisation
The retrieval module is a critical component of an RAG system, responsible for efficiently fetching relevant information from a large dataset or corpus. This module’s performance significantly impacts the overall effectiveness of RAG techniques, as the quality and relevance of the retrieved documents directly influence the generated responses. By optimizing the retrieval process within RAG techniques, the system can produce more accurate and contextually appropriate outputs.» Embedding-Based Retrieval:
- Contextual Embeddings: Using models like BERT (Bidirectional Encoder Representations from Transformers) or GPT (Generative Pre-trained Transformer) to generate dense vector representations of text. These embeddings capture semantic relationships and contextual information, improving the relevance of retrieved documents.
- Similarity Measures: Employing cosine similarity, Euclidean distance, or other metrics to compare embeddings and identify the most relevant documents. This approach enhances the retrieval accuracy by focusing on semantic rather than lexical similarity.
» Query Expansion and Reformulation:
- Synonym Expansion: Incorporate synonyms and related terms to broaden the search scope and retrieve more relevant documents.
- Contextual Reformulation: Modify the original query to better align with the structure and content of the corpus, improving the chances of retrieving pertinent information.
» Efficient Search Algorithms:
- BM25 (Best Matching 25): A probabilistic framework for information retrieval that ranks documents based on their relevance to the query. BM25 considers factors like term frequency, document length, and inverse document frequency to compute relevance scores.
- ANN (Approximate Nearest Neighbors): Techniques like Locality-Sensitive Hashing (LSH) and HNSW provide efficient solutions for high-dimensional similarity searches, enabling quick retrieval of relevant documents from large datasets.
3. RAG Post-Retrieval Optimisation
Post-retrieval optimization techniques are crucial for refining the output of Retrieval-Augmented Generation (RAG) techniques, ensuring that the generated content is accurate, relevant, and contextually appropriate. These techniques address the inherent challenges in the generation phase by enhancing the quality and coherence of the responses produced by RAG techniques.» Reranking Retrieved Documents
- Learning to Rank (LTR): LTR involves training a machine learning model to predict document relevance. The model utilizes features extracted from the query-document pairs to rank the documents. Common LTR algorithms include RankNet, LambdaMART, and BERT-based models.
- Feature Engineering: Extract meaningful features from the text, such as TF-IDF scores, BM25 scores, semantic embeddings, and metadata, is crucial for effective reranking.
» Fusion Strategies
- Score-Based Fusion: This technique involves combining the relevance scores from multiple models. For example, the scores from TF-IDF, BM25, and neural retrieval models can be aggregated to form a final relevance score.
- Rank-Based Fusion: Rank-based fusion methods combine the ranks assigned by different models. Techniques like CombSUM and CombMNZ aggregate the ranks and determine the final order of documents.
- Hybrid Approaches: Hybrid fusion strategies combine both score-based and rank-based methods. They leverage the strengths of both approaches to provide a more robust retrieval result.
» Feedback and Reinforcement Learning
- Explicit Feedback: Users provide direct feedback on the relevance and quality of the retrieved documents. This feedback can adjust the retrieval models and improve future results.
- Implicit Feedback: Implicit feedback involves analyzing user interactions, such as clicks, dwell time, and navigation patterns, to infer the relevance of the documents. ML models are trained on this implicit feedback to refine the retrieval and generation processes.
- Reinforcement Learning: Train a model to make sequential decisions based on user interactions. The model receives rewards or penalties based on the relevance of the generated responses. Techniques like Q-learning, Deep Q-Networks (DQN), and policy gradients are commonly used in RL to optimize retrieval and generation.
Quick takeaways for Production-ready RAG:
- Use distributed systems like Elasticsearch or Faiss for scalable and efficient retrieval.
- Distribute the load across multiple servers to handle high query volumes efficiently.
- Implement indexing and caching strategies to store and quickly retrieve frequently accessed data.
- Develop robust mechanisms to handle errors in both retrieval and generation phases.
- Monitor system performance and log critical metrics to detect and resolve issues promptly.